
As the AI revolution penetrates into more complex and critical domains, document parsing has emerged as a key foundation for large language models to "understand the world." The precision of extracting structured information from vast amounts of unstructured documents directly determines the efficiency of AI training and the depth of industrial application. Yet, the current landscape of parsing solutions is caught in a pervasive dilemma: they either rely on Supervised Fine-Tuning(SFT) to master known document types at the cost of failing on unseen layouts, or they sacrifice the broad multimodal prowess of large models in pursuit of specialized performance—a classic case of "focusing on one means neglecting the other."
Recently, INF TECH (INF) launched the industry's first reinforcement learning-based document parsing model — Infinity-Parser. By integrating a multi-aspect reward mechanism with the innovative technique of "layout-aware training for Vision-Language Models (VLM)", the model achieves dual breakthroughs in parsing accuracy and generalization capability. Crucially, it accomplishes this without sacrificing its multimodal understanding and reasoning abilities, thereby resolving the core industry dilemma by unifying "precise parsing" with "general intelligence." In the authoritative olmOCR-Bench benchmark, Infinity-Parser surpassed leading OCR models, including DeepSeek-OCR, MinerU2.5, and PaddleOCR-VL, setting a new state-of-the-art in document parsing.
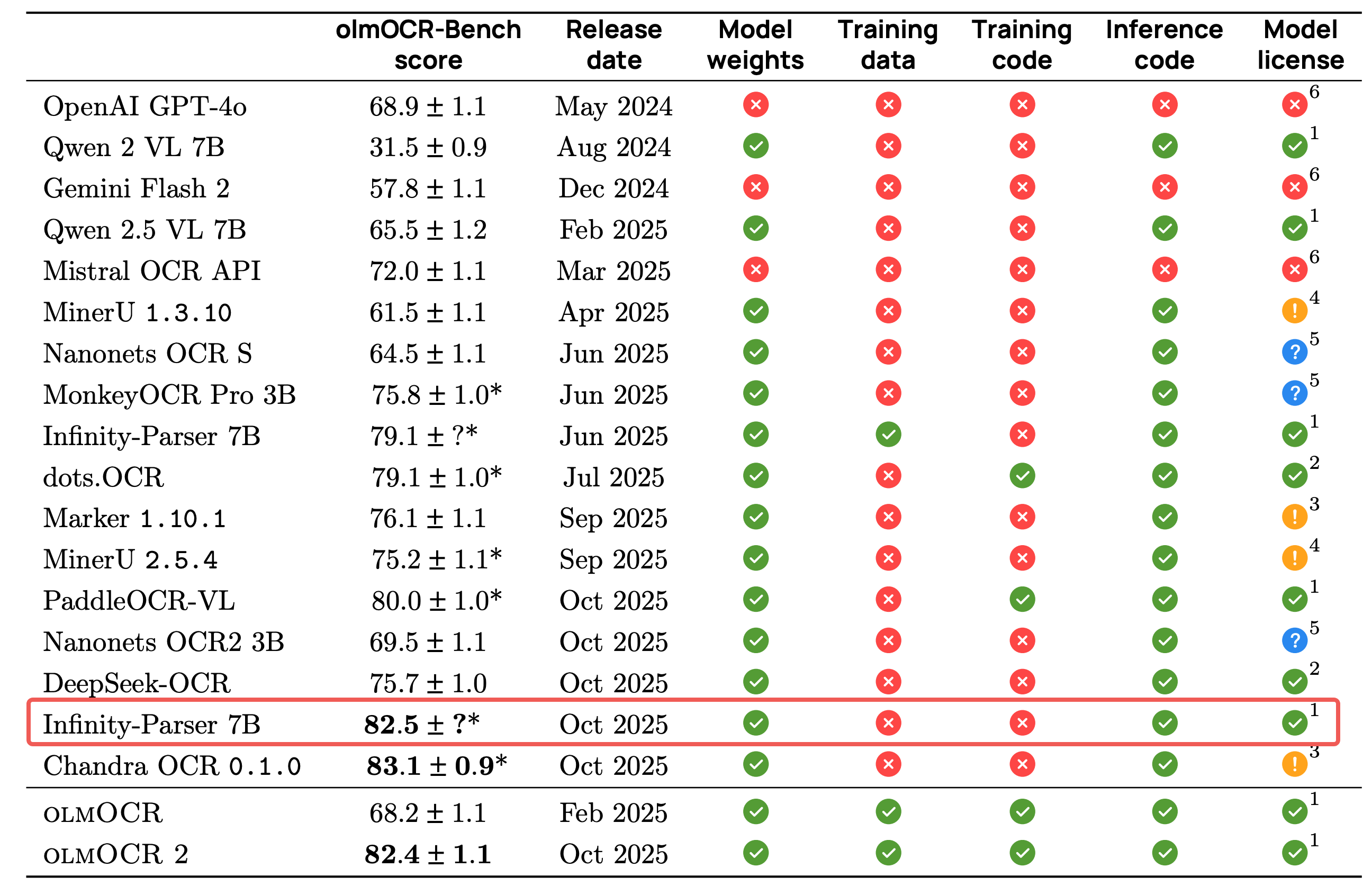
The '?' in the chart has an actual value of standard deviation 1.0. Metric source: Evaluation results from Allen Institute for AI (allenai) https://arxiv.org/pdf/2510.19817
Breakthrough in Accuracy: Understanding Document Structure "Like Humans"
Nowadays, multimodal large models have become standard, the core challenge of equipping them with "keen eyesight" lies in upgrading from "recognizing text" to "understanding structure." Confronted with massive unstructured data from web pages, documents, and scanned books, conventional parsing models struggle to comprehend logical structures. Mainstream solutions rely on Supervised Fine-Tuning, forcing models to "rote-learn" document rules, which makes it difficult for them to understand and reconstruct documents "like humans."
In the self-developed multimodal model, Infinity-Parser, the INF team introduced a multi-aspect reward mechanism focusing on content, structure, and sequence. This approach delivered impressive gains in parsing accuracy for the document types covered in training. Infinity-Parser now achieves precise table recognition, image semantic understanding, and visual element segmentation, aligning more closely with the human approach to document comprehension—first grasping the overall layout, then reading specific content. Especially in complex layout scenarios—such as multi-column formats, interspersed images and text, and irregular tables—it significantly enhances parsing accuracy and robustness, breaking through the limitation of "recognizing only text, not structure."
Consider the financial sector as an example. Externally disclosed corporate information is typically stored in PDF documents containing numerous intricate charts and tables, which demand exceptionally high parsing accuracy. When processing financial reports with complex tables, traditional OCR models can recognize all text but fail to accurately interpret borderless tables, complex row-column structures, and text reading order. In contrast, Infinity-Parser can correctly parse table border ranges, perceive row-column correspondences, and reconstruct text reading order, thereby restoring the document's complete information and structure with superior fidelity. In practical financial business scenarios, Infinity-Parser's performance in financial report parsing is top-tier, and supports international multilingual trading markets. The proprietary version continues to focus on financial document scenarios, and its parsing accuracy leads the industry.
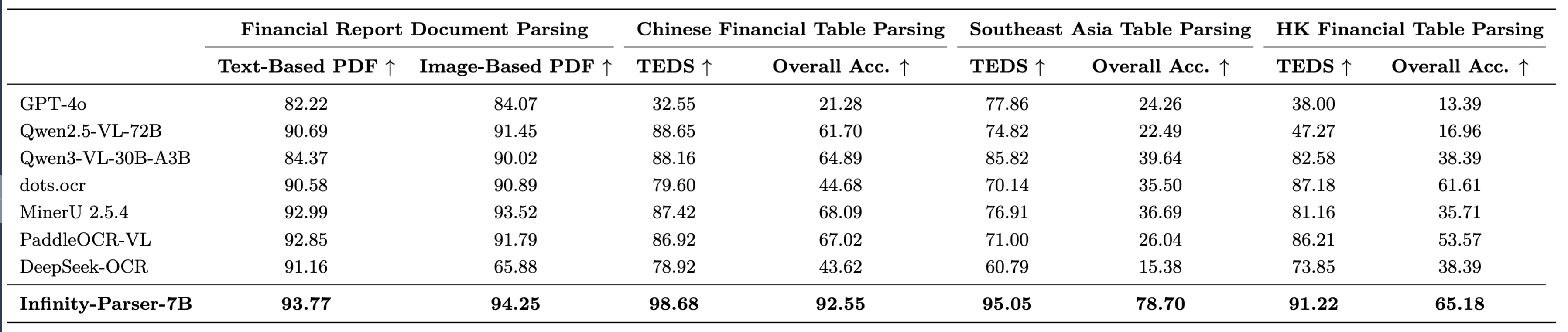 In practical financial business scenarios, the Infinity-Parser-7B model demonstrates superior performance. The evaluation metrics are of the INF proprietary model.
In practical financial business scenarios, the Infinity-Parser-7B model demonstrates superior performance. The evaluation metrics are of the INF proprietary model.
Generalization Upgrade: Handling Unseen Scenarios with "Inductive Reasoning"
In real-world industrial applications, document layouts are immensely diverse. New scenarios featuring "new fonts, multilingual mixes, and handwritten annotations" are ubiquitous. However, high-quality, large-scale, multi-layout document parsing data remains extremely scarce. Most public datasets are still plagued by issues such as OCR errors, inconsistent structural annotations, missing element labels, and hierarchical inaccuracies. These constraints not only limit model performance but also compromise the reliability, efficiency, and commercial value of AI implementation, compelling the industry to seek more robust solutions.
To tackle core industry challenges—including the scarcity of high-quality parsing data and limited layout generalization—the INF team adopted a dual-path strategy. Beyond the multi-aspect reward mechanism, they implemented a high-quality synthetic data generation pipeline, creating the Infinity-Doc-400K dataset. This approach rapidly supplements training data for layout-specific or structural blind spots, significantly enhancing Infinity-Parser's generalization on long-tail and unseen document types. Through multiple validation rounds, the model has demonstrated superior page-level structural awareness, enabling it to better capture global semantics and hierarchical relationships. It also exhibits stronger cross-type adaptability when parsing complex, out-of-distribution documents from non-training scenarios.
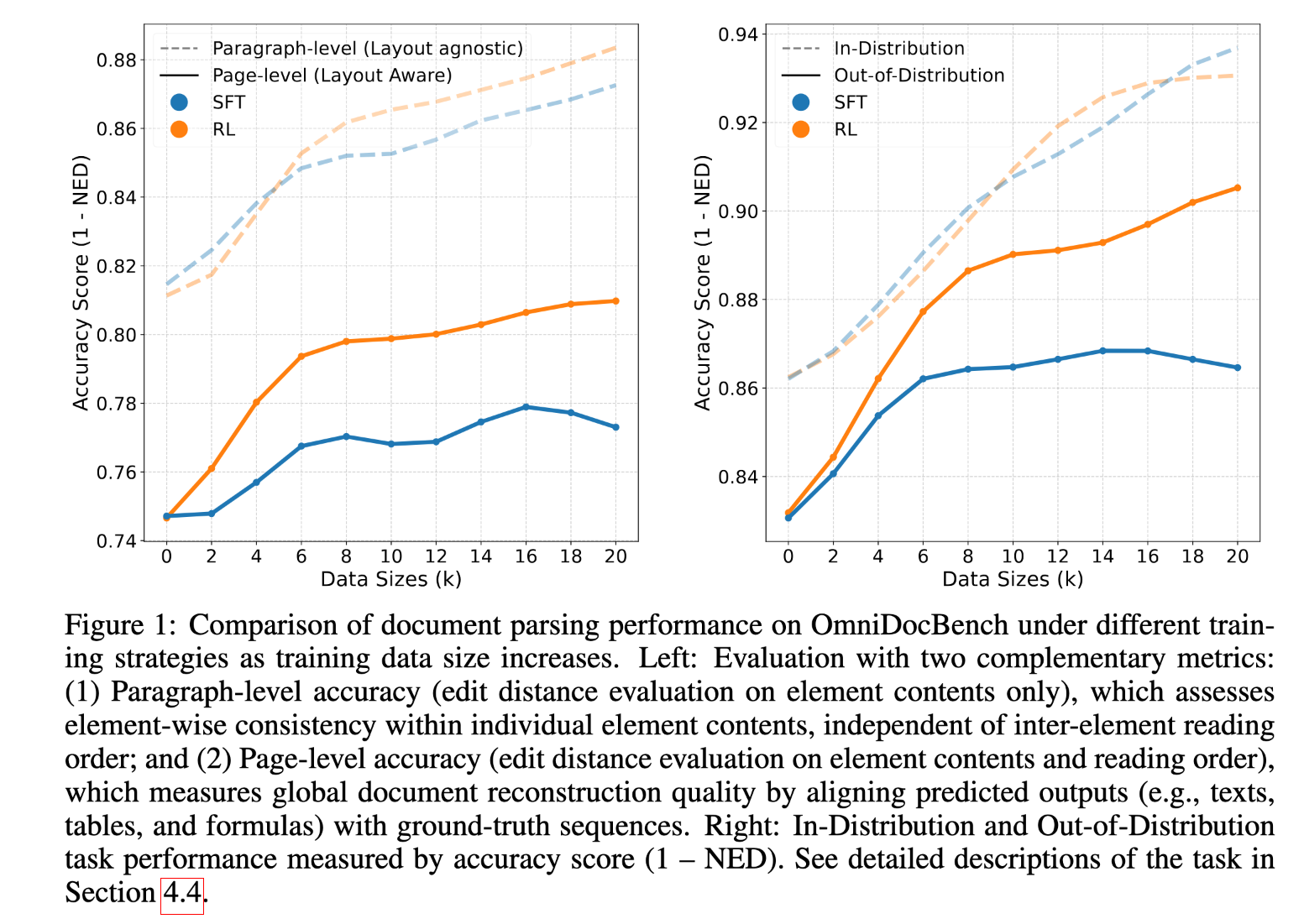 Faced with complex document scenarios, the model maintains robust generalization performance.
Faced with complex document scenarios, the model maintains robust generalization performance.
Strong generalization in document parsing amplifies the value of AI-powered industrialization across multiple dimensions. In the financial sector, for instance, a single model can cover the vast majority of document types, drastically reducing business intelligence costs. When processing international financial reports, it efficiently interprets tables with mixed languages—such as Chinese, English, and Japanese—across varied layouts, and extracts data accurately. This capability allows AI to integrate more deeply into business workflows, becoming not only usable but decisively effective.
Multimodal Compatibility + Open-Source Ecosystem: From "Specialized Tool" to "Ecological Foundation"
Notably, although optimized for document parsing, Infinity-Parser fully retains its multimodal understanding and reasoning capabilities, as evidenced by its performance on general benchmarks. This successfully mitigates the "catastrophic forgetting" commonly faced by large models during industry-specific SFT. Furthermore, by open-sourcing the high-quality Infinity-Doc-400K dataset, the INF aims to foster industry-wide collaboration in advancing document parsing technology.
 Baseline is Qwen2.5-VL-7B. All metrics are evaluated based on the LMMS-Eval benchmark framework.
Baseline is Qwen2.5-VL-7B. All metrics are evaluated based on the LMMS-Eval benchmark framework.
Leveraging its leading full-stack trustworthy AI technology system, INF horizontally integrates platform services across "computing power, toolchain, model, and application," while vertically deepening its focus in two core domains: finance and education. INF has launched products including the Dynamic Stock Index Compilation Solution and the INF Inspire Platform.
Nowadays when vision-language multimodal tasks are increasingly critical, the 7B-parameter Infinity-Parser provides a leading document parsing solution. It serves as a pivotal piece in the puzzle of "Trustworthy Generative AI Accelerating Industrial Implementation", driving the fusion of technology with business scenarios and continuously delivering innovative momentum for the intelligent transformation of industries.
Links:
- Technical Report: https://arxiv.org/pdf/2506.03197
- Code: https://github.com/infly-ai/INF-MLLM
- Open Source Data: https://huggingface.co/datasets/infly/Infinity-Doc-400K
- Open Source Weights: https://huggingface.co/infly/Infinity-Parser-7B
- Demo: https://huggingface.co/spaces/infly/Infinity-Parser-Demo