
随着AI产业落地进入深水区,文档解析能力已成为大模型 “理解世界” 的关键底座 —— 能否从海量非结构化文档中精准提取结构化信息,直接决定了 AI 训练的效率与产业落地的深度。然而,当前主流解析方案普遍陷入 “两难困境”:要么依赖监督微调(SFT)专精于已知文档类型,却在未知版式前 “失效”;要么为追求专精丢失大模型的通用多模态能力,陷入 “顾此失彼” 的瓶颈。
近日,无限光年(INF)推出业界首个基于强化学习的文档解析模型——Infinity-Parser。 该模型以多维度强化奖励机制为核心,通过 “布局感知训练视觉语言模型(VLM)” 的创新路径,在解析精度、泛化能力上实现双突破,同时完整保留多模态理解与推理能力,真正实现 “精准解析” 与 “通用智能” 的兼容。在权威评测 olmOCR-Bench 中,其性能超越 DeepSeek-OCR、MinerU2.5、PaddleOCR-VL 等顶尖 OCR 模型,树立了文档解析领域的新标杆。
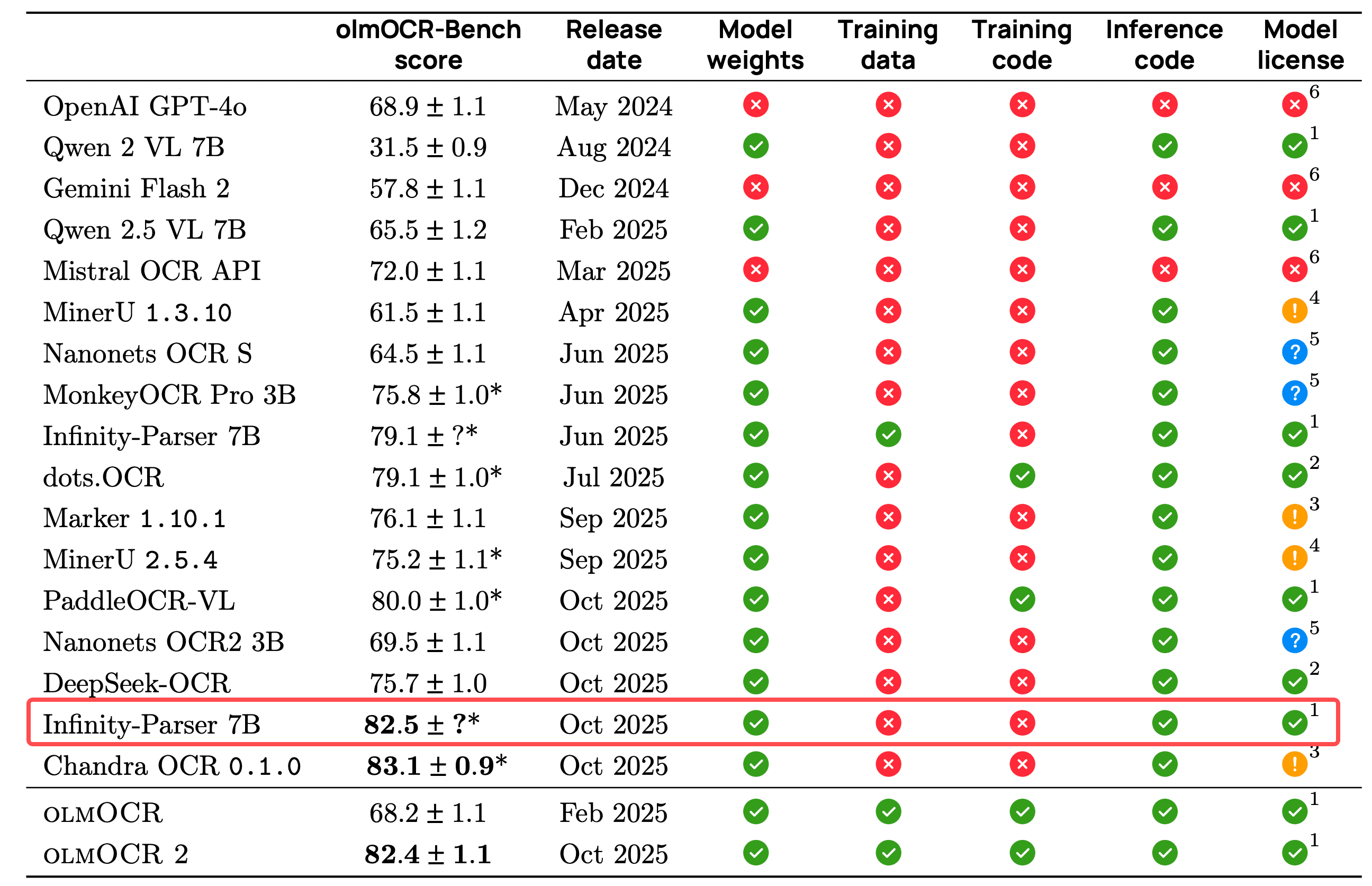
注:图中的'?'实际值为标准差1.0。指标来源:美国allenai实验室的评测结果 https://arxiv.org/pdf/2510.19817
精度突破: “像人一样” 理解文档结构
当下,多模态大模型成为标配,如何为大模型打造一双“慧眼”,其核心挑战在于让模型从 “识别文字” 升级为 “理解结构”。面对来自于网页、文档、扫描书籍等海量非结构化数据,传播模型难以理解逻辑结构,主流方案则依赖 SFT 让模型 “死记硬背” 文档规则,难以“像人一样”地理解和还原文档。
相比传统训练,INF团队在自主研发多模态模型Infinity-Parser中,围绕内容、结构、顺序三个角度,在强化学习阶段引入了多维度奖励机制,一举在训练覆盖的文档类型解析精度上取得亮眼成绩。目前,Infinity-Parser可实现精准的表格识别、图像语义理解、视觉元素分割,更贴近人类对文档的理解方式(先看整体布局,再读具体内容),尤其在复杂版面(如多栏混排、图文交叉、不规则表格)场景中,能显著提升解析的准确性和鲁棒性,突破 “只认文字不认结构” 的局限。
以金融场景为例,企业对外披露信息均存储在PDF文档,图表多且交叉排布,对文档解析精准度要求更高。面对带复杂表格的财务报告,传统OCR模型能识别所有文字,但无法准确地理解“无框表格、复杂行列结构和文字阅读顺序”。Infinity-Parser则能正确地“解析表格边框范围、感知行列对应关系、重建文字阅读顺序” ,更精准地还原文档的完整信息,更好地理解内容与结构。在实际的金融业务场景,Infinity-Parser的财报解析处于顶尖水平,支持多语种的国际化交易市场。INF内部专用版本持续深耕金融文档场景,解析准确率领先业界。
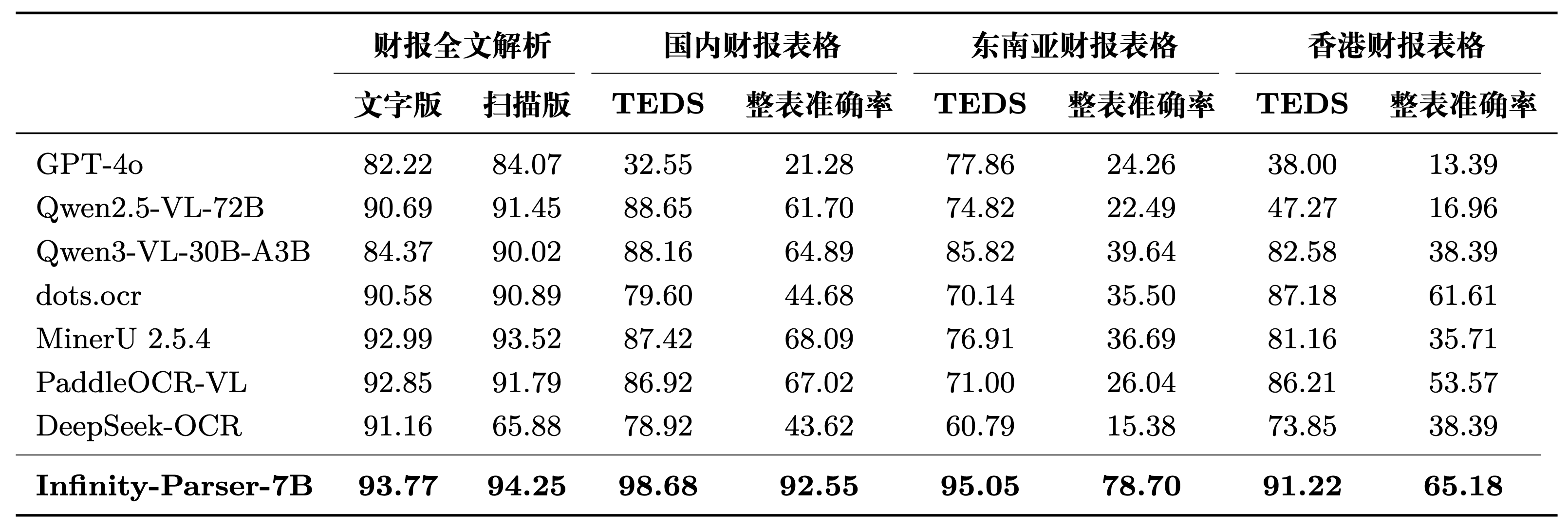
在实际金融业务场景,Infinity-Parser-7B模型效果更优。指标为内部工具评测的内部模型结果。
泛化升级:“举一反三” 应对未知场景
真实产业场景中,文档版式千变万化,“新字体、多语言混排、手写批注”新版面场景无处不在。但目前高质量、大规模、多版面类型的文档解析数据极度稀缺,大部分公开数据集中仍存在OCR错误、结构标注不一致、元素漏标或层级错误等问题。这些制约模型解析能力的原因,也影响着AI技术落地的可靠性、效率和商业价值,倒逼业内持续寻找更高效的解决方案。
立足高质量文档解析数据匮乏和版面窄化等行业难题,INF团队双管齐下。除了引入多维度奖励机制外,INF还采用高质量的合成数据生成机制,构建了高质量数据集Infinity-Doc-400K,为Infinity-Parser快速补充特定版式或结构盲区的训练数据,提升模型在长尾和未见版式上的泛化能力。经过多轮验证,Infinity-Parser在页面整体结构感知上展现出更强优势,能够更好地捕捉文档的全局语义与层级关系。同时,在域外分布的非训练场景的复杂文档解析中,也展现出更强的跨类型适应能力。
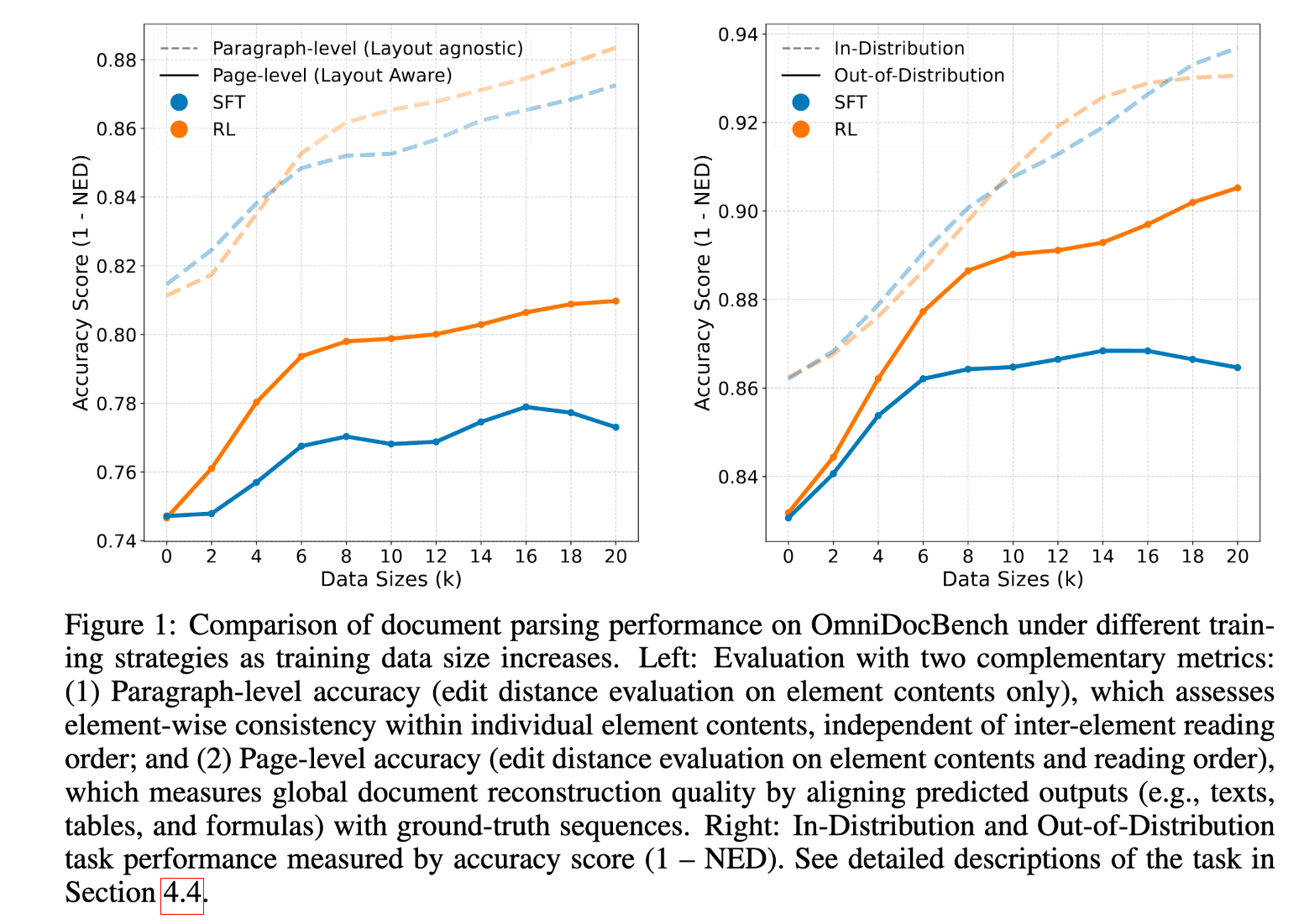
注:面对复杂文档场景,模型依然保持稳健的泛化性能。
良好的文档解析泛化能力,将从多个维度放大AI赋能产业的价值。对金融机构而言,一套模型即可覆盖绝大多数的文档类型,直接降低业务智能化成本,让其在处理全球客户的财报时,高效识别中英日等多语言混排、不同版式的表格并精准提取数据,让AI深入业务场景如虎添翼,真正可用。
多模态兼容 + 开源生态:从 “专精工具” 到 “生态底座”
值得关注的是,尽管Infinity-Parser针对文档解析任务进行了优化,但模型在通用多模态基准上仍完整保留多模态理解与推理能力,为行业展开SFT训练时大模型普遍出现的“灾难性遗忘”探索了新路径。此外,INF团队已将高质量数据集Infinity-Doc-400K开源,以开放共享的态度携手行业持续突破文档解析技术边界。

注:Baseline 为 Qwen2.5-VL-7B,所有指标均基于 LMMS-Eval 基准框架进行测评。
INF依托领先的可信AI全栈技术体系,横向打通“算力—工具链—模型—应用”平台服务能力,纵向深耕金融与教育两大核心领域,推出了股票指数动态编制解决方案和启智智算平台等产品。在视觉与语言多模态任务日益关键的今天,Infinity-Parser以7B的参数量,提供了一个领先的文档解析解决方案,成为 “可信生成式 AI 加速产业落地” 的重要拼图,驱动技术与业务场景融合,为千行百业智能化持续输出创新动能。
相关链接:
1.论文链接: https://arxiv.org/pdf/2506.03197
2.相关代码: https://github.com/infly-ai/INF-MLLM
3.开源数据: https://huggingface.co/datasets/infly/Infinity-Doc-400K
4.开源权重: https://huggingface.co/infly/Infinity-Parser-7B
5.体验页面: https://huggingface.co/spaces/infly/Infinity-Parser-Demo